从 pg_log 自动提取 SQL Plan 程序源码
1. 功能说明
从 postgresql_xxx.log 日志(auto_explain 抓取)中自动分析并提取慢 SQL Plan(自动去重)。
去重机制逻辑如下
- ✅ SQL 相同但计划结构不同(表名/索引名/操作符类型不同) → 均保留
- ✅ SQL 相同且计划结构相同(表名/索引名/操作符类型相同) → 只保留第一次出现的
- ✅ 使用传参的相同 SQL → 视为同一条 SQL(参数值不影响去重)
- ✅ 计划结构相同但数值不同(统计信息/cost/actual time/rows等数值不同) → 视为相同条目(只保留第一次出现的)
2. 使用方法
直接将该 Python 程序放到日志文件所在目录下执行,它会自动分析当前目录下的所有 *.log 日志文件。
3. 示例
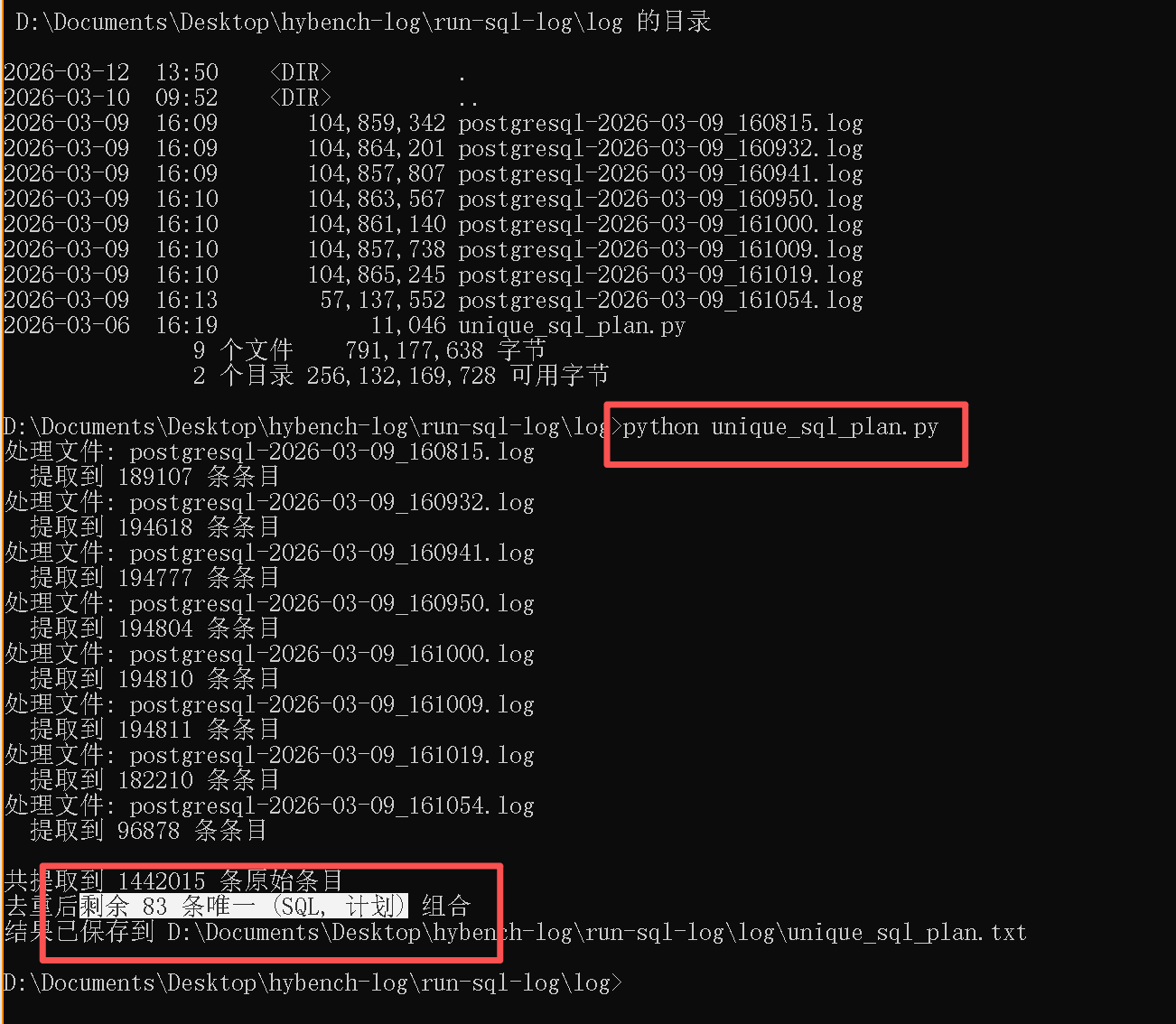
从 8 个 postgresql-2026-xxxx.log 文件中,共提取到 1,442,015 条原始 SQL 语句,去重后剩余 83 条唯一 (SQL, 计划) 组合,并保存在当前目录下的 unique_sql_plan.txt 文件中。
执行过程
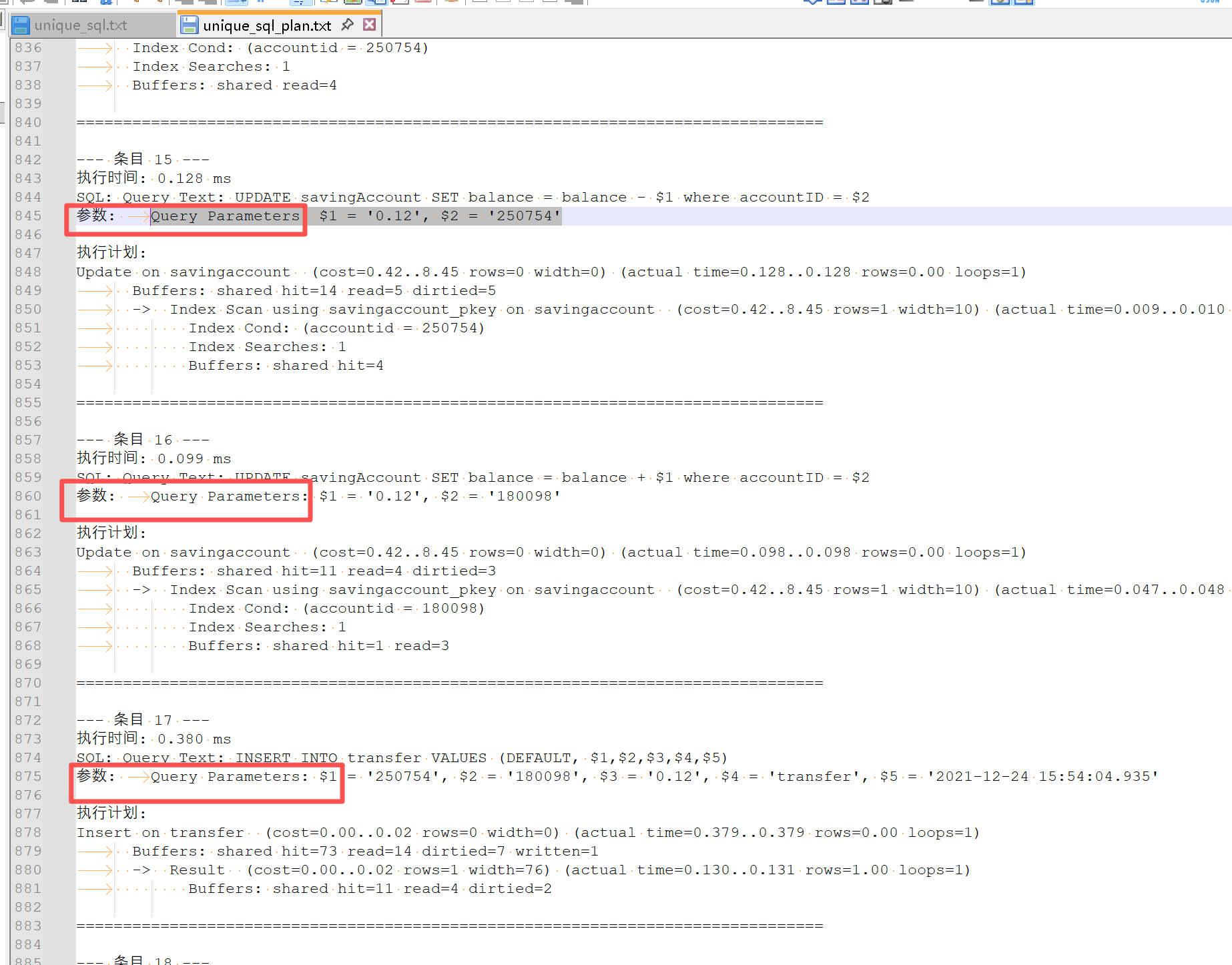
执行结果
4. 源码
4.1 unique_sql_plan.py
## ***== cat unique_sql_plan.py ==***
## ***== All rights reserved. ==***
## ***== Copyright © dbnotes.cn. ==***
import re
import glob
import os
from collections import OrderedDict
# 扩展的操作符列表,包括所有可能的计划节点
PLAN_KEYWORDS = {
'->', 'Aggregate', 'Append', 'Bitmap Heap Scan', 'Bitmap Index Scan', 'BitmapOr',
'CTE Scan', 'Custom Scan', 'Delete', 'Foreign Scan', 'Function Scan',
'Gather', 'Gather Merge', 'Group', 'GroupAggregate', 'Hash', 'Hash Join',
'Hash Left Join', 'Hash Right Join', 'Hash Full Join', 'HashAggregate',
'Incremental Sort', 'Index Only Scan', 'Index Scan', 'Insert', 'Limit',
'LockRows', 'Materialize', 'Memoize', 'Merge Append', 'Merge Join',
'Merge Left Join', 'Merge Right Join', 'Merge Full Join', 'ModifyTable',
'Nested Loop', 'Nested Loop Left Join', 'Nested Loop Right Join', 'Nested Loop Full Join',
'Parallel Seq Scan', 'ProjectSet', 'Recursive Union', 'Result', 'Seq Scan',
'SetOp', 'Sort', 'Subquery Scan', 'TableFunc Scan', 'Tid Scan', 'Unique',
'Update', 'Values Scan', 'WindowAgg', 'Workers'
}
# 需要完全忽略的行模式(执行细节)
IGNORE_PATTERNS = [
r'^\s*Buffers:',
r'^\s*Storage:',
r'^\s*Memory Usage:',
r'^\s*Heap Fetches:',
r'^\s*Index Searches:',
r'^\s*JIT:',
r'^\s*Buckets:.*Batches:',
r'^\s*Worker\s+\d+:',
r'^\s*Workers Planned:',
r'^\s*Workers Launched:',
r'^\s*Execution Time:',
r'^\s*Planning Time:',
r'^\s*Heap Blocks:',
r'^\s*Hits:.*Misses:.*Evictions:.*Overflows:',
r'^\s*Rows Removed by Filter:',
r'^\s*Cache Mode: logical',
r'^\s*Sort Method:',
r'^\s*Sort Key:',
r'^\s*Group Key:',
r'^\s*Hash Cond:',
r'^\s*Join Filter:',
r'^\s*Recheck Cond:',
r'^\s*Filter:',
r'^\s*Index Cond:',
r'^\s*Presorted Key:',
r'^\s*Full-sort Groups:',
r'^\s*Average Memory:',
r'^\s*Peak Memory:',
r'^\s*Pre-sorted Groups:',
r'^\s*Batches:',
r'^\s*Memory Usage:',
r'^\s*Disk Usage:',
r'^\s*Functions:',
r'^\s*Options:',
r'^\s*Timing:',
r'^\s*Generation:',
r'^\s*Inlining:',
r'^\s*Optimization:',
r'^\s*Emission:',
r'^\s*Total:',
r'^\s*Cache Key:',
r'^\s*Cache Mode:',
r'^\s*Hits:',
r'^\s*Misses:',
r'^\s*Evictions:',
r'^\s*Overflows:',
r'^\s*Memory Usage:',
r'^\s*Storage:',
]
def normalize_sql(sql):
"""压缩空白,用于去重(不影响输出的原始格式)"""
if not sql:
return ''
return re.sub(r'\s+', ' ', sql).strip()
def normalize_plan(plan):
"""
规范化计划文本:移除所有执行细节行,保留结构骨架。
对保留的结构行:
- 去除行首所有空白
- 移除成本括号 (cost=...)
- 移除实际执行时间括号 (actual time=...)
- 移除 "(never executed)" 标记
- 将独立数字(整数/小数)替换为 '#'
- 压缩内部连续空白为一个空格
返回一个无缩进的、按行连接的字符串,用于比较计划结构是否相同。
"""
if not plan:
return ''
lines = plan.splitlines()
cleaned_lines = []
for line in lines:
# 检查是否应完全忽略该行
ignore = False
for pat in IGNORE_PATTERNS:
if re.match(pat, line):
ignore = True
break
if ignore:
continue
# 移除成本括号 (cost=...)
line = re.sub(r'\s*\(cost=[^)]*\)', '', line)
# 移除实际执行时间括号 (actual time=...)
line = re.sub(r'\s*\(actual time[^)]*\)', '', line)
# 移除 "(never executed)" 标记
line = re.sub(r'\s*\(never executed\)', '', line)
# 去除行首所有空白
stripped = line.lstrip()
if not stripped:
continue
# 将行中所有独立数字替换为 '#'
# \b 确保不会匹配到标识符中的数字(如下划线后的数字)
cleaned = re.sub(r'\b\d+(?:\.\d+)?\b', '#', stripped)
# 压缩内部连续空白为一个空格(避免因缩进/空格差异导致误判)
cleaned = re.sub(r'\s+', ' ', cleaned)
if cleaned:
cleaned_lines.append(cleaned)
return '\n'.join(cleaned_lines)
def extract_entry_from_file(filepath):
"""
从单个日志文件中提取所有条目信息。
每个条目包含:执行时间、SQL、参数、执行计划。
返回列表,每个元素为字典:
{
'exec_time': str, # 原始执行时间字符串(如 "0.889 ms")
'sql': str,
'params': str, # 参数字符串,如果没有则为空字符串
'plan': str # 计划文本,如果没有则为空字符串
}
"""
entries = []
try:
with open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
lines = f.readlines()
except Exception as e:
print(f"读取文件 {filepath} 出错: {e}")
return entries
i = 0
n = len(lines)
while i < n:
line = lines[i]
if 'LOG: duration:' in line:
# 提取执行时间
exec_time_match = re.search(r'duration:\s*([\d.]+)\s*ms', line)
exec_time = exec_time_match.group(1) + ' ms' if exec_time_match else ''
# 开始收集条目内容(后续所有行直到下一个 LOG:)
i += 1
block_lines = []
while i < n and 'LOG:' not in lines[i]:
block_lines.append(lines[i].rstrip('\n'))
i += 1
# 初始化条目各部分
sql_lines = []
params = ''
plan_lines = []
# 在 block_lines 中查找 SQL 起始行(Query Text: 或 statement: 或 SQL:)
sql_start_idx = -1
sql_prefix = None
for idx, bline in enumerate(block_lines):
stripped = bline.lstrip()
if stripped.startswith('Query Text:'):
sql_prefix = 'Query Text:'
sql_start_idx = idx
break
elif stripped.startswith('statement:'):
sql_prefix = 'statement:'
sql_start_idx = idx
break
elif stripped.startswith('SQL:'):
sql_prefix = 'SQL:'
sql_start_idx = idx
break
if sql_start_idx == -1:
continue # 未找到 SQL 起始行,跳过
# 获取 SQL 的第一行(去除前缀)
first_sql_line = re.sub(r'^(Query Text:|statement:|SQL:)\s*', '', block_lines[sql_start_idx])
sql_lines.append(first_sql_line)
# 从 SQL 起始行的下一行开始扫描,收集 SQL 直到遇到参数行或计划开始行
## ***== Copyright © databasenotes ==***
param_idx = -1
plan_start_idx = -1
for k in range(sql_start_idx + 1, len(block_lines)):
current_line = block_lines[k]
stripped_line = current_line.lstrip()
# 检查是否为参数行
if (stripped_line.startswith('Query Parameters:') or
stripped_line.startswith('parameters:') or
stripped_line.startswith('参数:')):
param_idx = k
# 提取参数值(去除前缀)
params_raw = re.sub(r'^(Query Parameters:|parameters:|参数:)\s*', '', current_line)
if params_raw.startswith(':'):
params_raw = params_raw[1:].lstrip()
params = params_raw
break # 遇到参数行,SQL 结束
# 检查是否为计划开始行(包含 cost= 的行)
if 'cost=' in current_line:
# 可能是一行计划,停止 SQL 收集,并记录计划开始位置
plan_start_idx = k
break
# 如果不是参数行也不是计划开始行,则加入 SQL
sql_lines.append(current_line)
# 如果遇到了参数行,计划应从参数行的下一行开始
if param_idx != -1:
# 从参数行之后寻找计划开始行
for k in range(param_idx + 1, len(block_lines)):
if 'cost=' in block_lines[k] or block_lines[k].lstrip().split(None,1)[0] in PLAN_KEYWORDS:
plan_start_idx = k
break
# 如果没找到,可能是没有计划?但通常会有计划
# 如果已经找到 plan_start_idx(来自 SQL 收集过程中),直接使用
# 收集计划行
if plan_start_idx != -1:
for k in range(plan_start_idx, len(block_lines)):
plan_lines.append(block_lines[k])
# 构建条目
sql = '\n'.join(sql_lines).strip()
plan = '\n'.join(plan_lines).strip()
if sql:
entries.append({
'exec_time': exec_time,
'sql': sql,
'params': params,
'plan': plan
})
else:
i += 1
return entries
def process_logs(log_pattern='postgresql-*.log', output_file='unique_sql_plan.txt'):
"""批量处理日志文件,输出 (SQL, 计划) 去重后的结果(保留原始格式)"""
## ***== Copyright © databasenotes ==***
all_entries = []
file_list = sorted(glob.glob(log_pattern))
if not file_list:
print("未找到匹配的日志文件,请检查模式。")
return
for filepath in file_list:
print(f"处理文件: {filepath}")
entries = extract_entry_from_file(filepath)
print(f" 提取到 {len(entries)} 条条目")
all_entries.extend(entries)
print(f"\n共提取到 {len(all_entries)} 条原始条目")
# 去重:以规范化后的 (SQL, 计划) 为唯一键
unique_dict = OrderedDict()
for entry in all_entries:
key = (normalize_sql(entry['sql']), normalize_plan(entry['plan']))
if key not in unique_dict:
unique_dict[key] = entry
print(f"去重后剩余 {len(unique_dict)} 条唯一 (SQL, 计划) 组合")
# 写入输出文件(保留原始格式)
## ***== Copyright © databasenotes ==***
with open(output_file, 'w', encoding='utf-8') as out:
for idx, entry in enumerate(unique_dict.values(), 1):
out.write(f"--- 条目 {idx} ---\n")
if entry['exec_time']:
out.write(f"执行时间: {entry['exec_time']}\n")
out.write(f"SQL: {entry['sql']}\n")
if entry['params']:
out.write(f"参数: {entry['params']}\n")
out.write("\n执行计划:\n")
if entry['plan']:
out.write(entry['plan'] + "\n")
else:
out.write("(无计划记录)\n")
out.write("\n" + "="*80 + "\n\n")
print(f"结果已保存到 {os.path.abspath(output_file)}")
if __name__ == "__main__":
process_logs()